
Vision Language Models e IA Multimodal: Por qué los LLM de tu empresa son ciegos y cómo curarlos

Dec 3, 2024
Carmen Pérez Serrano
Artificial Intelligence
Traditional LLMs are blind
It is no secret that Artificial Intelligence has come to stay. Specifically, McKinsey found that more than 65% of companies already use AI -which tripled in no more than 10 months. As the number of AI enterprise use cases grows in complexity and adoption, the technology’s state of the art keeps evolving. This requires corporate users and developers to stay up-to-date with the latest trends to ensure their AI systems remain competitive and efficient.
Large Language Models (“LLMs”) have been in the spotlight for a while now, especially due to the popularity they harvested with the rise of Generative AI -which enabled the democratization of this technology. Today, LLMs are the model of choice: due to their versatility and scalability -and to some extent also due to their popularity. These models are the cornerstone of most enterprise AI systems or tools.
Nevertheless, as reliable and popular as these large models are, LLMs are not enterprises’ only choice. And they are surely not a choice without limitations. Among such limitations, one stands out: traditional LLMs cannot process images or visual data. Traditional Large Language Models are blind.
Even when LLMs are used for text processing and analysis only, this “blindness” poses a problem still. We can think of these models as being able to “hear” and understand words, but as unable to “see” -thus, unable to contextualize- information in more visual environments. Alas, the lack of context.
If models can process (textual) information but cannot contextualize it, models are not really understanding information. This is a perfect recipe for hallucinations, as well as a critical blow to accuracy, resulting from all the context and (visual) information that the model fails to process and analyze.
Sad fact: most LLMs do not perform well in real-world enterprise environments.
Proof: data.world found out in one of its benchmarks that a popular LLM achieved a 16.7% average execution accuracy. That is not great news. Especially considering most AI are not coy when it comes to giving *facts* instead of answers.
The vision challenges prove further troublesome in industries such as legal or finance, in which -as core as semantic analysis is- systems also require a certain visual context to literally “get the full picture”.
This is where Visual Language Models (“VLMs”) come into play.
What Are VLMs?
Vision Language Models or VLMs are models that incorporate vision capabilities. These vision models can be LLMs or Small Language Models (if you do not know what SLMs start here). VLMs can process and analyze text while they are also capable of working with visual data -something traditional LLMs were unable to do. Thus, VLMs result from the combination of a vision model and a language model and, in a sense, are the logical “next step” in the evolution of LLMs. In a nutshell:
Text only = LLM (or SLM)
Text + image = VLM
As a result, VLMs can overcome critical challenges traditional LLMs face. From obvious challenges such as vision-related use cases (like image classification) to -equally important but- less obvious ones like in-document figure interpretation. Specifically, some tasks Visual Language Models can perform that their text-only counterparts could not include:
Describing images
Answering image-related questions
Image retrieval based on text (and the other way around)
Accurate document data extraction
In this context, one of this year’s buzzwords: “multimodal AI”. Multimodal AI refers to those AI systems capable of integrating, processing, and analyzing information and input of different formats (such as text, image, or audio) and consequently producing outputs. Just like we humans do! Multimodality is a prerequisite for human-like comprehension, and inherently this implies the utilization of VLMs -models that are visual as well as textual.
A report by MIT predicts how the multimodal AI market is expected to grow at an average annual rate of 32.2% between 2019 and 2030. Supported by such figures are Henry Ajder’s -founder of Latent Space and renowned AI expert- words: “There is no doubt that any chief digital transformation officers or chief AI officers worth their salt will be aware of multimodal AI and are going to be thinking very carefully about what it can do for them”. The European Space Agency seconds this, and goes as far as considering multimodality the “missing piece” for the autonomous vehicle puzzle in its articles.
Even though multimodal AI has been in the spotlight for a while, it is still a developing concept in practice. Nevertheless, there is no doubt that today’s VLMs will play a big role in the multimodal AI of the future.
In Renaiss AI we work closely with companies in materializing their AI use cases. Even though model selection will depend on the specifics of the use case at hand, we favor VLMs for several reasons. The present article explores these reasons, together with vision’s impact on AI system functionality in enterprise use-case environments.
Enterprise environments: nothing to “see” here?
The obvious problem: vision-based use cases
In the past year alone, AI models have progressed from understanding text alone -or processing visual data alone- to featuring this “multimodality” and being able to interpret and produce outputs in both text and images.
As enterprises seek to leverage AI for more sophisticated tasks, Vision Language Models offer distinct advantages over traditional LLMs by integrating multimodal data for more evolved insights and automation. There is a wide range of use cases for which the need for computer vision is obvious. Some illustrative examples:
Shelf stock control in supermarkets -needs vision
X-ray diagnostics in healthcare -needs vision
Object identification by self-driving cars -needs vision
Image creation and modification -(evidently) needs vision
Quality control in production chains -needs vision
We could continue listing use cases but you mostly likely got the point. But unless it is for one of these (image-based) use cases, most companies are currently using more straightforward, text-only, LLMs, and might think these work just fine.
This article aims to give visibility to the (painful) idea that text-only LLMs might be quietly jeopardizing project results. Even in literature-heavy industries vision might be imperative for accuracy. As we introduced at the beginning, this is mainly due to context.
The not-so-obvious problem: semantic use cases (and context!)
Context and visual elements
This is also the case with human comprehension: an isolated chunk of text will be difficult to understand. We need sentences to make sense of words, paragraphs to make sense of sentences, and pages to make sense of paragraphs. Now add figures to the equation. Tables, graphs, diagrams, pictures… this information provides the context. Without due vision, LLMs lack context.
In mass-data industries such as finance or healthcare, knowledge bases will without a question consist of information that is, by nature, intrinsically reliable on visual data -such as tables, charts, figures, or diagrams. When data repositories featuring such documentation are connected to a purely semantic LLM, the model will only be able to analyze text information -thus, not only ignoring visual data but also doing so implicitly and without warning the user.
If the answer to a prompt is found on a table, a text-only LLM will ignore such a table and search the text for something that resembles the answer in nature. The results will vary from slightly mistaken to complete (matter-of-factly) invention.
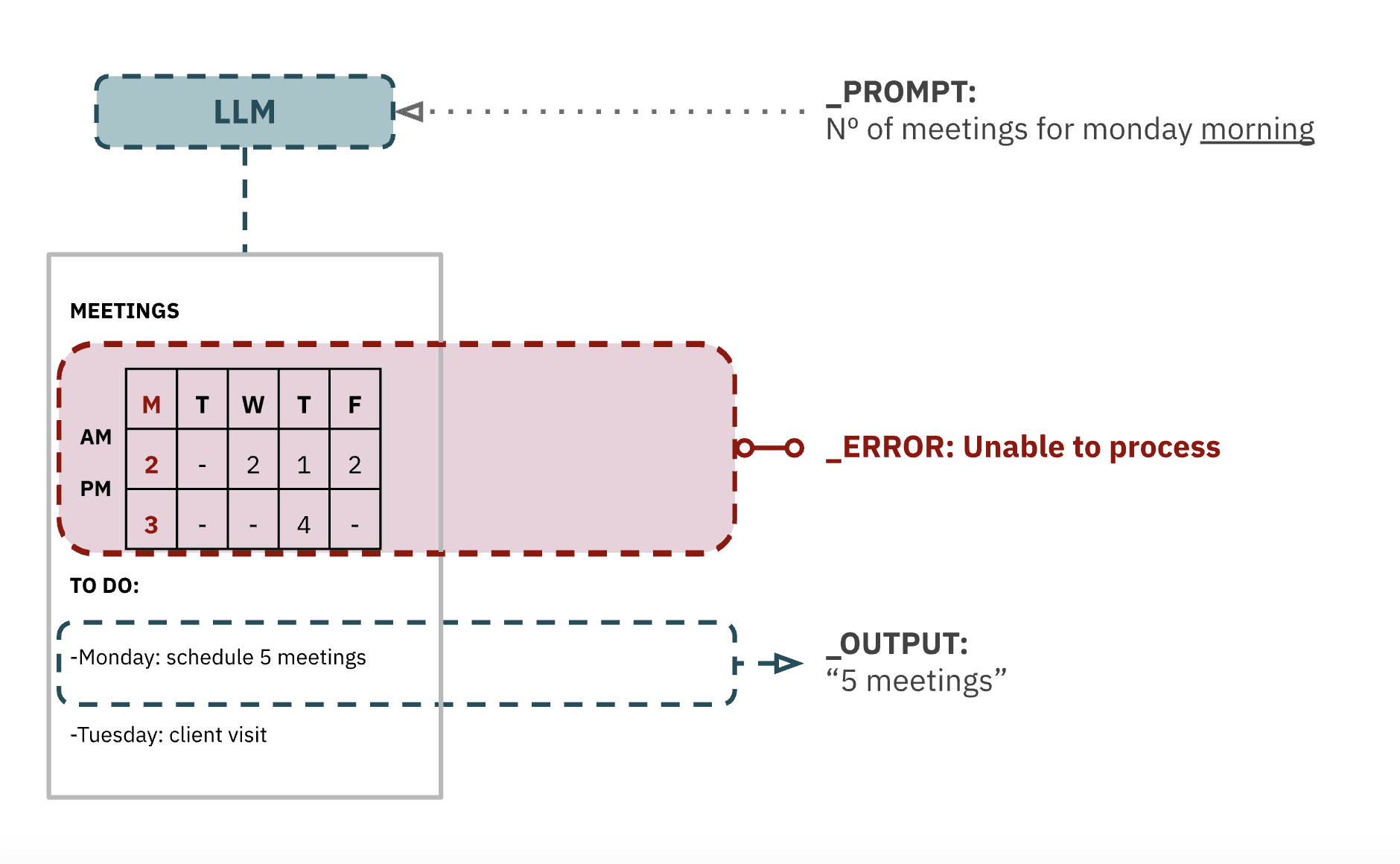
The illustration above summarizes how semantic LLMs (will not) deal with visual information, such as tables; a text-only LLM will confidently reply that the number of meetings for “Monday morning” is “five”, as the system would only be able to take into account semantic information.
This is why AI systems might fail at the most simple tasks, such as providing a document’s date -which is so obviously at the header of the document! Well, it may be for us, but traditional LLMs are “blind”; they are unable to tell a header from the body of a document, or a title from a subtitle.
Further aggravating the problem, not only is any potentially relevant visual data not considered for responses, but users will be utterly unaware of this fact, as GenAI excels at making the most absurd answers look like textbook history.
Context and chunking
Also due to their lack of vision -thus of spatial awareness- text-only LLMs will have a rough time analyzing structured documents such as legal contracts. To process lengthier documents, most text-only LLMs will require that these documents be divided into segments referred to as “chunks” -then they can process each chunk, as opposed to the whole document at once.
Chunks will be designed to cover more or less information depending on their specific purpose (and no, a chunk that covers more information is not systematically better). While it must be acknowledged that the efficiency of the “chunking” technique will depend on both task complexity and the methodology (or library) used, there are systemic challenges to even the most curated “chunking” techniques. The main challenge is contextualization; information is contextualized within a given chunk, but then the context is restricted to that individual chunk -therefore losing all connection to information within separate chunks.
As another illustrative example, legal professionals may not realize this but when they ask their legal text-only LLM-based AI system to “check the confidentiality clause and list any potential threats” for a given legal agreement, outputs might be flawed as:
The system might be unable to correctly identify the “confidentiality clause” if it is not properly marked on the document or if the chunking technique is not sufficiently polished -especially if there are other clauses within the document that mention confidentiality. Bear in mind the system cannot identify titles or text styling.
In those cases where the confidentiality clause can be duly identified, even with the most advanced chunking, models may ignore one or more paragraphs therein -as these may fall outside the scope of a given “chunk”. The longer a clause is the more problematic this gets.
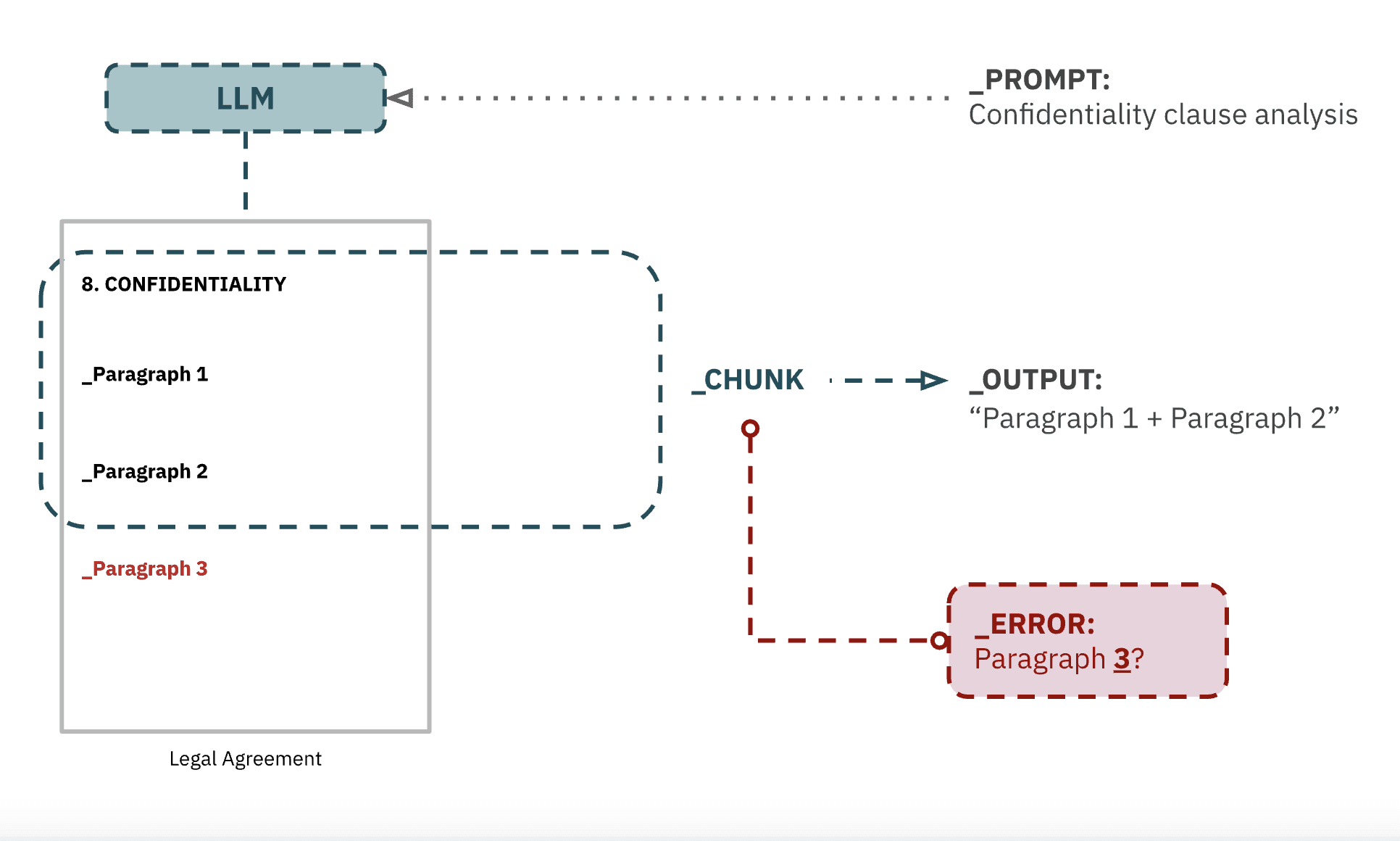
For context-dependent prompts, most LLMs will play a “chunking lottery”; as a result, information valuable to a certain prompt may or may not end up outside of the context of a relevant chunk. This enormously hinders the accuracy of systems, increasing the hallucination potential.
Clearly then, the solution is asking legal teams for shorter confidentiality clauses. (This is a joke. Just in case it was not clear.) The solution is VLMs.
One VLM is worth a thousand LLMs
At least for most enterprises. Both issues described above (the obvious and the not-so-obvious) are already disturbing when observed in a vacuum. Now, imagine the effect of real-world corporate environments with great volumes of (all kinds of, complex) data on the accuracy of LLMs. Then add intricate prompts to the equation. That is the recipe for hallucination.
Sure, data can be arranged and organized in such a way as to ensure compatibility with the applicable model -but imagine the amount of time and resources (including financial resources) such a Sisyphean task would imply. OR you could ensure your company utilizes VLMs for any AI use case, regardless of the lack of an “obvious” necessity for image processing. As above exposed, even the most strictly semantic tasks require vision for integral understanding and adequate accuracy.
AI models get “smarter” the better they replicate human logic processes -and human intelligence is predominantly visual and fully contextual. At Renaiss AI we envision that, in the future, the vast majority of LLMs will “come to their senses” and incorporate vision features.
In the meantime, do make sure your AI projects (and their underlying models) do not “lose sight” of what matters. Accuracy in real environments. Contact us if you need guidance.
