
Vision Language Models e IA Multimodal: Por qué los LLM de tu empresa son ciegos y cómo curarlos

3 dic 2024
Carmen Pérez Serrano
Artificial Intelligence
Los LLMs tradicionales son ciegos
No es ningún secreto que la Inteligencia Artificial ha llegado para quedarse. En concreto, y según McKinsey, más del 65% de las empresas ya utilizan IA -cifra que se ha triplicado en tan sólo 10 meses. A medida que el número de casos de uso de IA empresariales crece en complejidad y adopción, el estado del arte sigue evolucionando. Esto exige a usuarios y desarrolladores corporativos mantenerse al día de las últimas tendencias a fin de garantizar que sus sistemas de IA se mantengan competitivos y eficientes en el tiempo.
Los Large Language Models (“LLMs”, por sus siglas en inglés) llevan ya tiempo en el punto de mira, especialmente debido a la popularidad que ganaron con el auge de la IA generativa -la cual permitió la democratización de esta tecnología. Hoy en día, los LLM son el modelo por excelencia debido a su versatilidad y escalabilidad -y en cierta medida, también a su popularidad. Así, estos modelos son también la elección habitual en la mayoría de sistemas o herramientas de IA empresarial.
Sin embargo, por fiables y populares que sean, los LLM no son la única opción que tienen las empresas. Y, desde luego, no son una opción sin limitaciones. Entre esas limitaciones, destaca una: los LLM tradicionales no pueden procesar imágenes ni datos visuales. Los LLMs tradicionales son ciegos.
Incluso en aquellos casos en los que un LLM se utilizan para procesar y analizar texto exclusivamente, esta “ceguera” sigue planteando un problema; podemos imaginar estos modelos como capaces de “oír” y comprender palabras, pero incapaces de “ver” (y, por tanto, incapaces de contextualizar) información en entornos visuales. Resultado: una (problemática) falta de contexto.
La primera conclusión lógica es que, si los modelos pueden procesar información (textual) pero no pueden contextualizarla, estos modelos no están entendiendo de verdad la información. Otra conclusión es que esto es una receta perfecta para las alucinaciones, así como un golpe crítico a la precisión o “accuracy” de un modelo, que resulta, inevitablemente, del contexto e información (visual) que el modelo no logra procesar.
¿La (triste) realidad?: la mayoría de LLMs no funcionan bien en entornos empresariales.
Prueba: data.world descubrió en uno de sus benchmarks que un (popular) LLM obtenía una precisión de ejecución media del 16,7%... No es la mejor noticia, especialmente teniendo en cuenta que la mayoría de sistemas de IA no dudan en escupir datos ficticios como si de *hechos* se tratasen
El problema de la visión resulta aún más acuciante en sectores como el jurídico o el financiero, en los que -por importante que sea el análisis semántico- los modelos también requieren de un cierto contexto visual para tomar decisiones “informadas”.
Aquí la gran utilidad de los Modelos de Lenguaje Visual o Visual Language Models (“VLMs” por sus siglas en inglés).
¿Qué son los VLMs?
Los VLMs son modelos de Inteligencia Artificial que incorporan habilidades de visión. Estos modelos pueden ser LLMs o Small Language Models (si todavía no sabes qué es un SLM, empieza por aquí). Los VLM pueden procesar y analizar texto, pero además son capaces de trabajar con datos visuales -algo imposible para los LLM tradicionales. Así, los VLM resultan de la combinación de un modelo de visión y un modelo de lenguaje y, en un sentido, son el siguiente paso lógico en la cadena evolutiva de los LLM. En resumen:
Sólo texto = LLM (o SLM)
Texto + imagen = VLM
Como resultado, los VLMs son capaces de superar obstáculos que para los LLMs tradicionales venían siendo insalvables. Desde problemas evidentes, tales como aquellos casos de uso relacionados con visión computacional (por ejemplo, la clasificación de imágenes), hasta la interpretación de figuras o gráficos dentro de un documento. A modo ilustrativo, algunas de las tareas que los modelos de lenguaje visual pueden realizar y que sus homólogos encontrarán prácticamente imposibles son:
Descripción de imágenes
Resolución de preguntas relacionadas con imágenes
El “retrieval” de imágenes a partir de texto (y viceversa)
Extracción de datos precisa
En este contexto encontramos uno de los términos del momento: la “multimodalidad”. La IA multimodal comprende aquellos sistemas de IA capaces de integrar, procesar y analizar información y entradas de distintos formatos (como texto, imagen o audio) y de producir resultados en consecuencia. ¡Tal y como hacemos las personas!. La multimodalidad es requisito indispensable para una comprensión comparable a la humana, y esto conlleva necesariamente la utilización de VLMs -modelos semánticos que incorporen visión.
Un informe del MIT predice que el mercado de la IA multimodal crezca a una tasa media anual del 32,2% entre 2019 y 2030. En la misma línea, las palabras de Henry Ajder, fundador de Latent Space y reconocido experto en materia IA, que avisa a los directores de IA y transformación digital de la importancia que tendrá la IA multimodal y sus funciones en el ámbito empresarial. La Agencia Espacial Europea se suma a este discurso, llegando a considerar, en uno de sus artículos, a la IA multimodal como la “pieza” que completará el rompecabezas de los vehículos autónomos.
Aunque el uso del concepto de la multimodalidad no es nuevo, lo cierto es que esta tecnología sigue encontrándose en una etapa muy incipiente. Incluso así, no cabe duda de que los VLMs del presente desempeñarán un papel fundamental en la multimodalidad del futuro.
En Renaiss AI trabajamos en estrecha colaboración con empresas de diferentes sectores en el desarrollo de sus casos de uso de IA. Si bien la selección de un determinado modelo de IA dependerá de las especificidades del caso de uso al que éste se destine, nosotros abogamos por el uso de VLMs por diferentes motivos. El presente artículo tiene por objeto la exploración de dichos motivos, así como del impacto de la visión en entornos de casos de uso de IA empresariales.
Entornos empresariales: aquí no hay nada que “ver”…
El problema obvio: casos de uso de visión
Sólo en el último año, los modelos de IA han pasado de ser estrictamente semánticos -o estrictamente visuales- a presentar esta multimodalidad y ser capaces de interpretar y producir resultados tanto en texto como en imágenes.
A medida que la IA se democratiza, las empresas buscan implementar esta tecnología para procesos de cada vez mayor sofisticación; y es en este ámbito que los VLM se desenvuelven mejor, al tener la capacidad de integrar datos multimodales que permitirán a los sistemas arrojar mejores resultados y acceder a un nuevo nivel de automatización de tareas. En este sentido, existe una amplia gama de casos de uso que, por su naturaleza, requerirían de visión computacional intrínseca. A ejemplos ilustrativos:
Control de stocks en supermercados -requiere visión
Diagnóstico en rayos-X -requiere visión
Identificación de elementos en vehículos autónomos
Creación y edición de imágenes -(obviamente) requiere visión
Control de calidad en cadenas de producción -visión, visión, VISIÓN
Y así, incontables casos de uso. La necesidad de un sistema de IA que pueda procesar información visual es más que evidente en este tipo de use cases (de ahí que este sea el problema “obvio”). Sin embargo, fuera de los casos de uso intrínsecamente visuales, la mayoría de compañías utilizan LLMs tradicionales y puramente semánticos. Y creen que éstos son suficientes (pista: probablemente no lo son).
Este artículo tiene, precisamente, por objeto dar visibilidad a la (dolorosa) realidad de muchos proyectos: sus resultados se están viendo comprometidos debido al uso de LLMs puramente semánticos. Y el (segundo) mejor momento para darse cuenta es ahora. Incluso en aquellas industrias pura e históricamente lingüísticas, la visión es prerrequisito para la funcionalidad de los sistemas. La razón ya la hemos adelantado: contexto.
El problema menos obvio: casos de uso semánticos (¡contexto!)
Elementos visuales y contexto
La lógica artificial y la humana no son tan diferentes en naturaleza: un párrafo de texto, aislado y descontextualizado, podría llegar a resultarnos difícil de comprender. Necesitamos frases para dar sentido a las palabras, párrafos para dar sentido a las frases y páginas para dar sentido a los párrafos. Y ahora añade un par de ilustraciones a la ecuación. Tablas, gráficos, diagramas, imágenes... toda esta es la información que conforma el contexto. Y toda esta es la información que, sin funcionalidades de visión, los LLM pasan por alto. Consecuencia: los LLMs no pueden contextualizar información.
En sectores característicamente dependientes de grandes volúmenes de datos, como el financiero o el sanitario, las bases de datos contendrán información que, necesariamente, dependerá de datos visuales (tablas, gráficos, diagramas…) para su comprensión integral. Si alimentamos un LLM cualquiera con este tipo de bases de datos, debemos ser conscientes de que el modelo será capaz de analizar única y exclusivamente la información semántica contenida en los mismos. Dicho modelo no se limitará a ignorar los datos visuales, sino que además lo hará sin aviso alguno.
Así, si la respuesta a una pregunta se encuentra en formato tabla, un LLM de texto ignorará dicha tabla y buscará, entre el texto, lo que más se asimile en naturaleza a una respuesta. Y eso será lo que arroje. Como es lógico, el resultado variará de ligeramente erróneo a ficción absoluta (eso sí, disfrazada de verdad universal).
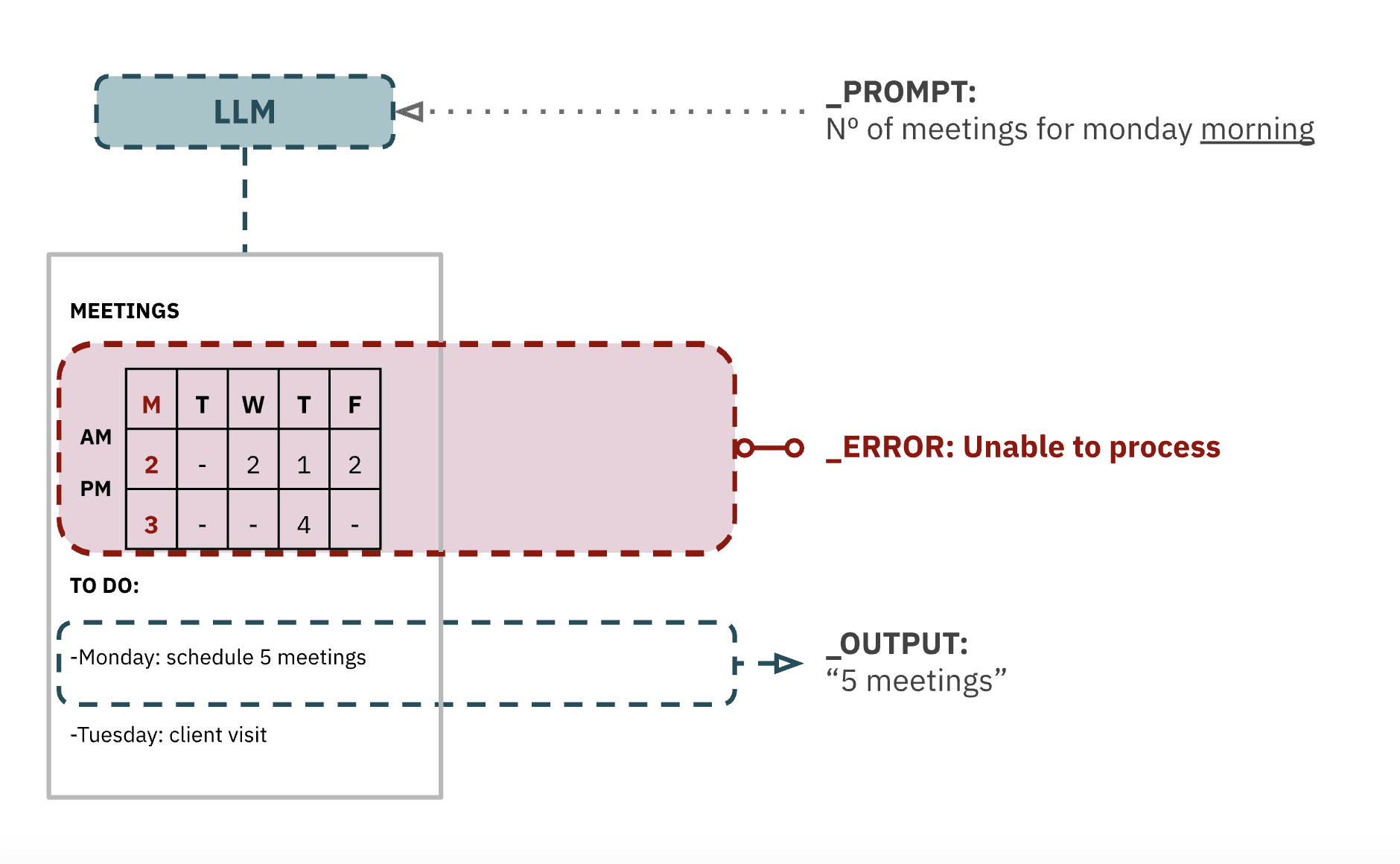
La imagen arriba ilustra cómo los LLM semánticos (en absolutamente todos los casos) ignoran información visual, tal y como una tabla. Tal modelo responderá (con insultante seguridad, además) que el “número de reuniones del lunes por la mañana” es cinco, ya que se limitaría a procesar el texto del documento.
He aquí el por qué las IAs en ocasiones fallan en las tareas más sencillas, como, por ejemplo, proporcionar la fecha de un documento -que OBVIAMENTE está en el encabezado; los LLMs tradicionales son ciegos, no pueden ver el encabezado. Ni distinguir un encabezado del cuerpo de un documento. O un título de un subtítulo.
A mayor abundamiento, el ya mencionado problema de la sobreconfianza de los modelos: la mayoría de modelos que no tengan la información suficiente responderán igualmente. Y lo que es mejor (peor) aún, tienen la genial capacidad de hacer que la respuesta más absurda parezca parafraseada de un libro de un libro de historia. Y esto es, precisamente, lo que hará un LLM aunque la respuesta esté en una imagen que no puede procesar.
“Chunking” y el contexto
Debido a su falta de visión, y por tanto de noción espacial, los LLM semánticos tendrán problemas a la hora de analizar documentos estructurados, como por ejemplo contratos. Habitualmente, los LLMs requieren que los documentos de mayor extensión sean divididos en segmentos para poder procesarlos; estos segmentos reciben el nombre de chunks. Así, el modelo podrá procesar cada chunk por separado, en lugar del documento entero de golpe.
El alcance de los chunkings se definirá en función del propósito específico al que sirvan (y no, el que un chunk cubra más información no lo hará sistemáticamente mejor).
Si bien la eficacia de una determinada técnica de chunking dependerá siempre de la metodología (o librería) empleada y de la complejidad de la tarea, existen problemas estructurales inherentes al chunking y de los que adolecen incluso las técnicas más curadas. El principal es la contextualización: al contextualizarse la información dentro de un chunk específico, se limita todo el contexto a un solo segmento, a la vez que se pierde toda información fuera de sus límites y dentro de otros chunks.
En este sentido, otro ejemplo ilustrativo: los profesionales jurídicos pueden no darse cuenta de que, cuando piden a su herramienta de IA legal de turno (probablemente basada en LLM semántico) que “revise la cláusula de confidencialidad y enumere los posibles riesgos” en base a un determinado contrato, la respuesta de esta herramienta puede ser incorrecta por distintos motivos:
Existe la posibilidad de que el sistema sea directamente incapaz de identificar la cláusula de confidencialidad y diferenciarla de otras cláusulas, especialmente si ésta no está (semántica y) debidamente diferenciada y si la técnica de chunking no es lo suficientemente avanzada; especialmente si existen referencias a la “confidencialidad” dentro de otras cláusulas. Por obvio que parezca, el modelo no puede identificar títulos o estilos de texto.
Aunque el modelo haya sido capaz de identificar la cláusula correctamente, existe el riesgo, incluso con las técnicas de chunking más avanzadas, de que el modelo ignore uno o más párrafos de la misma si éstos caen fuera de un determinado chunk. A mayor extensión de la cláusula (o menor chunk), mayor problemática.
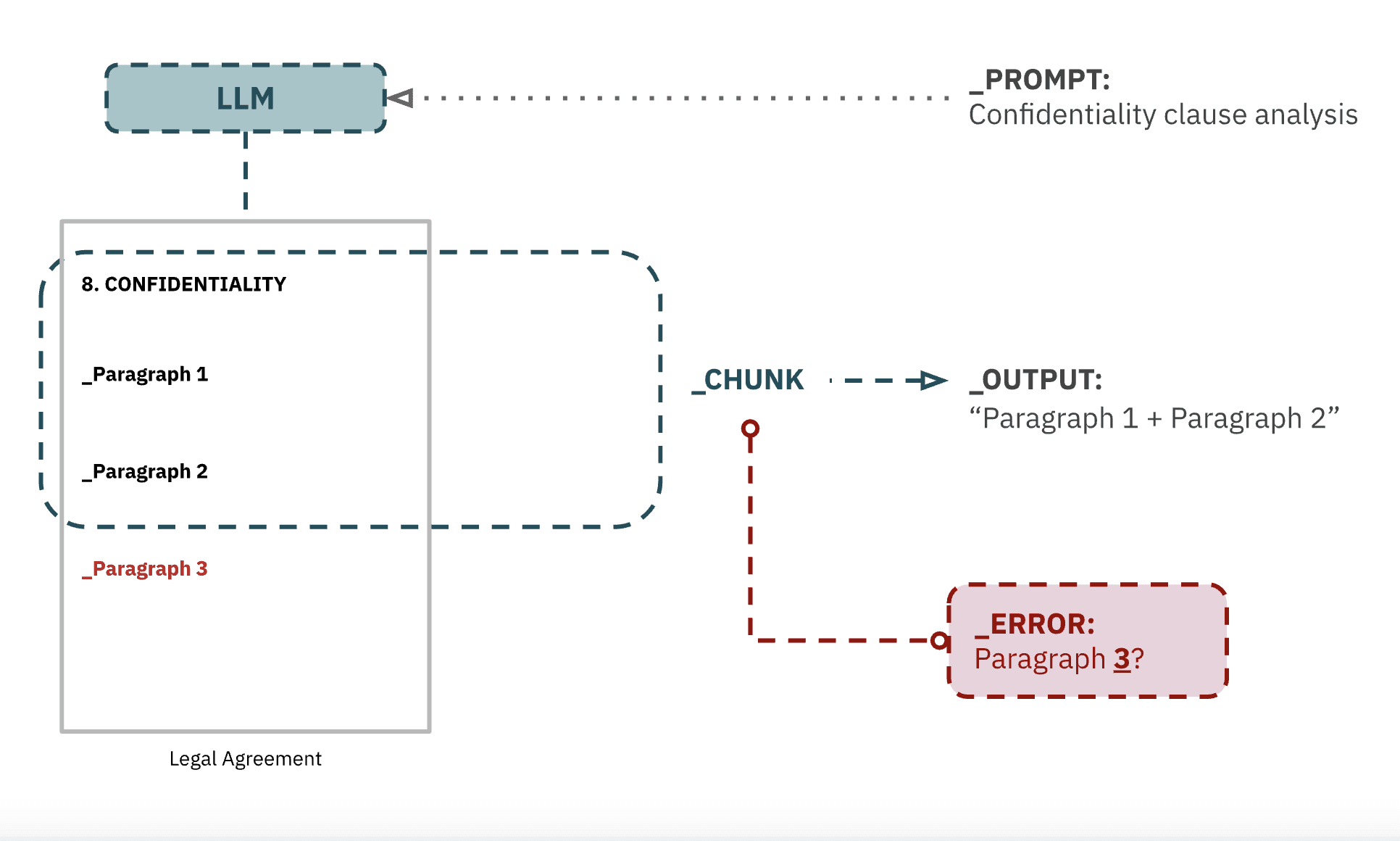
Ante prompts como estos, con mayor dependencia del contexto, los LLMs semánticos jugarán a una especie de lotería de chunks, y puede que (quizás si, quizás no) la información relevante para una tarea acabe fuera del chunk que el modelo seleccione. Esto penaliza considerablemente el accuracy de los sistemas, incrementando la posibilidad de alucinación.
En este caso la solución será solicitar a los equipos de legal que redacten cláusulas de confidencialidad más cortas. (Es broma. Por si la aclaración era necesaria) La solución son los VLMs.
¿Un VLM vale más que mil LLMs?
Al menos para la mayoría de empresas. Los problemas descritos anteriormente ya son, de por sí, preocupantes desde un punto de vista teórico. Ahora, imaginemos el efecto que tendría un entorno empresarial real, con grandes volúmenes de datos (de diferentes naturalezas, complejos) sobre el ratio de accuracy de un LLM. Y añadamos prompts enrevesados a la ecuación. Receta perfecta para alucinaciones.
Sí, los datos pueden estructurarse de tal manera que aseguremos su procesado, pero debemos tener en cuenta el nivel de tiempo y recursos (económicos también) que esta sisifeana tarea requeriría (y a largo plazo). O, nuestra empresa podría usar VLMs independientemente del caso de uso y de la aparente “irrelevancia” del procesado de imágenes. Tal y como hemos argumentado, incluso los modelos destinados a tareas puramente semánticas requieren de visión para una comprensión integral y un accuracy adecuado.
Los resultados de la Inteligencia Artificial son proporcionales a la capacidad de los modelos de replicar los procesos lógicos humanos -y la inteligencia humana es predominantemente visual y completamente contextual. En Renaiss AI, nuestra visión es que, en el futuro, la extensa mayoría de LLMs incorporarán visión de forma sistemática.
Mientras tanto, aconsejar que los proyectos (y sus modelos) no pierdan de vista sus prioridades. Funcionalidad en entornos reales. Contacta con nosotros si crees que podemos ayudarte.
